淺談AlphaGo演算法
本文作者陳重鈞為零機壹觸專欄作家,同時營運創科生意,有商管碩士學位,原文刊於作者網誌

在朋友fb 上的熱烈討論中﹐分享了少少有關AlphaGo的討論。在這裡正式深入淺出寫文,解釋 AlphaGo 神袐演算法背後的邏輯。筆者覺得大部分寫 AlphaGo 的文章或報道,都寫得一般人看不明。但實際上它的演算法,並不算是深奧的演算法。
AlphaGo 的演算法,是由四部分組成:
1. Value Network,一個 deep learning 的神經網絡(Convolutional/Space Invariant Artificial Neural Network, CANN/SIANN);
2&3. 兩個 Policy Network,一個快一個慢;
4. 所謂蒙地卡羅樹搜尋演算法,將整件事串合。
先談談蒙地卡羅樹搜尋(Monte Carlo Tree Search,一般都稱為 MCTS),其實這概念並不深奧,而且是在日常生活裡很常用的方法。
在電腦 algorithm 的範疇,講個「甚麼蒙地卡羅模擬」「甚麼蒙地卡羅方法」,其實都是和隨機有關。「蒙地卡羅方法」的定義,是「當一個問題未能夠用邏輯推理解決,就試用隨機方法解決,不斷隨機試試到正確為止」。最簡單的例子,例如年輕人未識選擇對象,嘗試跟不同異性去街,試試是否合得來;或大量買六合彩電腦票,都可以算是一種蒙地卡羅演算法。但正宗「蒙地卡羅方法」的意思,通常是用盡量多、數以萬計的隨機數,使到答案漸漸浮現出來。
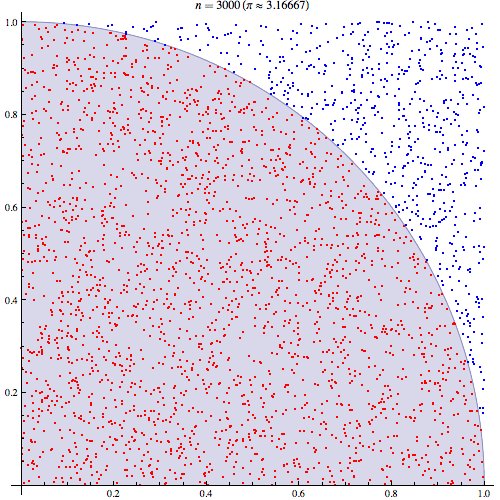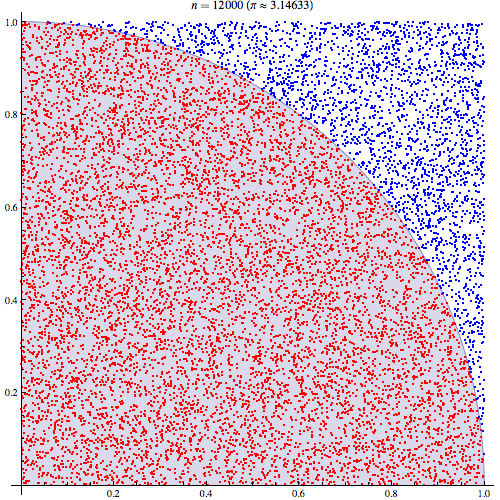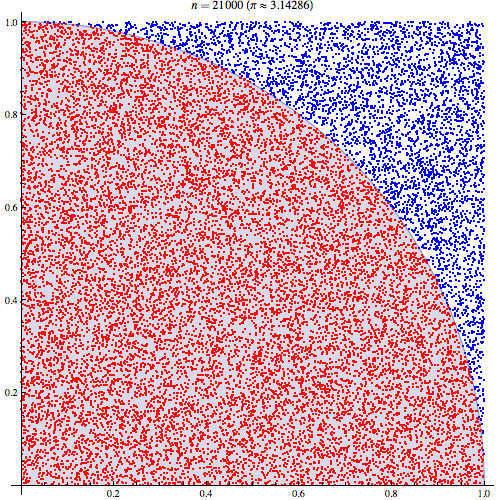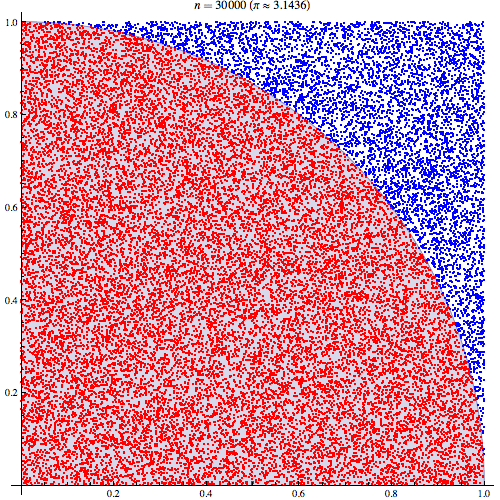
一個用「蒙地卡羅方法」找 pi 的演算法,每個紅點藍點都是一次隨機(圖片來源:維基百科)
圍棋是個經典電腦工程難題,主要原因是它的「遊戲樹」(game tree)大到電腦處理不到。遊戲樹就是所有的棋局可能性。「蒙地卡羅方法」用在圍棋上,就是不斷隨機地在這「遊戲樹」中揀不同的位置,然後用上文的三個神經網絡得出三個百分率,然後用這三個百分率去引導下棋。這便大概總括了 AlphaGo 的演算法。
稱為「蒙地卡羅樹」,是因為這個不斷隨機的嘗試,最終要收納為一個樹狀結構。
讀者讀到這裡,基本上可以不看下文講神經網絡,都算對 AlphaGo 的演算法有個概念。
繼續講講那三個神經網絡是做甚麼。
Value Network 只有一個,用途是「估計」現在的局勢,AlphaGo 自己的勝算是多少。「估計」打了星,是因為這真的是估計,而不是數學:因為是用神經網絡做。設計 AlphaGo 的電腦科學家,是以模擬人腦捉棋的思維去想。若你捉過棋,例如飛行棋、鬥獸棋也可以:通常捉到某處,你會大約腦中知道,自己是處於上風或下風。這個「處於上風或下風」的人腦估計,就是 Value Network 的主要功能。
神經網絡不是邏輯組成的,是個比較像人類的「感性思維」的技術。結構不複雜,讀 Computer Science 的大學一年級生也做到出來,結構詳情網上有很多,這篇主要講 AlphaGo 不贅。而且筆者會建議,看不明人工神經網絡的人,跳過不看,總之知道它是個「用電腦扮人腦」的演算法就可以。因為看不明這個,一樣可以明白 AlphaGo 的演算法。
其實用神經網絡去辨認圍棋格局,有點像用人工智能(下稱AI)認一張 19×19 pixel 闊的黑白相片。
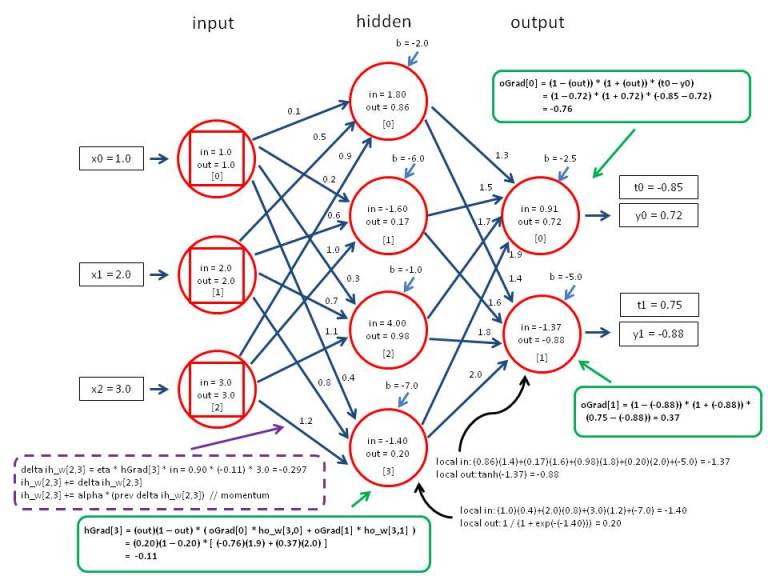
一個超級簡化的人工神經網絡模型,可用作解釋原理:左邊是輸入,要不斷以計算廻圈改線上的 weight 使右邊y=t,完成一個訓練數據。一般人工神經網絡都要用上百萬數據做數億廻圈以達致準確。(圖片來源:qcloud.com)
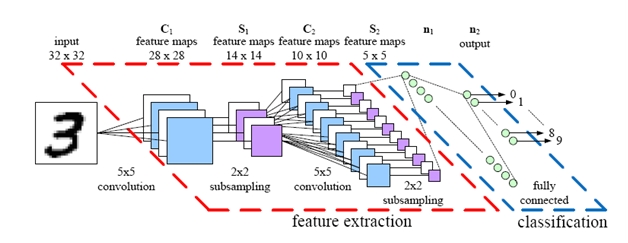
Convolutional Artificial Neural Network 的設計,右半由上圖的人工神經網絡組成(圖片來源:pyimagesearch)
講過 Value Network,便說說 Policy Network。這就是當你下棋時,例如飛行棋 / 鬥獸棋,通常到你行棋,你見到個棋局大約會有個「最有可能贏的下一步」的想法。Policy Network 做的就是這個功能。
快的 Policy Network 準確度較低,慢的 Policy Network 準確度較高。兩者都會用來估計下一步。AlphaGo 演算法中,亦加入了個「盡量不用太常見的下法」的變數。
以上便大約講解了 AlphaGo 的整個演算法。
有朋友提出疑問,在這裡寫一下。
問:AlphaGo 的技術可以用在其他地方嗎?
答:其實 AI 的演算法,好多都是只在該 AI 精通的地方可行,AlphaGo 也只是 ANI(Artificial Narrow Intelligence)。AlphaGo 可以用在其他棋類或遊戲上,但大部分遊戲都沒有需要,因為遊戲樹沒有圍棋大。而這個研究是啟發了電腦科學對包含神經網絡的 AI的潛能,提升期望。而包含神經網絡的 AI,則可以用在很多地方;AlphaGo 的示範是一個大到不能以邏輯或數學去完全計算的問題。
問:圍棋定麻雀複雜點?有無其他問題複雜過圍棋?
答:以人類歷史上發明過的遊戲,包括棋、賭博、電子遊戲,圍棋都是無出其右的。筆者在《信報》零機壹觸專欄講過:「國際象棋的遊戲樹大小為10^123(10的123次方);圍棋則是10^360。試比較中國象棋10^150,和黑白棋10^58。」 麻雀是 10^12。
問:其他人做不做到 AlphaGo?
答:大概做到。你只要找部大型電腦,輸入大量訓練資料,然後給它大量時間去訓練,並不斷嘗試提升準確度,大概都可以做到。不過這個程度的投資,不如做其他更有盈利的項目好過。
問:AlphaGo 象徵著甚麼?
答:圍棋一直以來都是人類最後防線。圍棋輸給電腦,正式揭開 AI 時代的序幕:電腦已在所有對戰遊戲中完勝人類。想像下:玩電腦第一身射擊遊戲,20人類對20電腦,電腦科學現有技術,已有能力 100 局 100 勝。
AlphaGo 的技術並不是新事,都是上世紀90年代已有;AlphaGo 的突破只是演算法,而不是科技。而且 AlphaGo 勝棋的原因,很大程度是它的龐大運算力和訓練時數。所以這事情上,對學術和專業領域的震撼不大,倒是很有娛樂性。
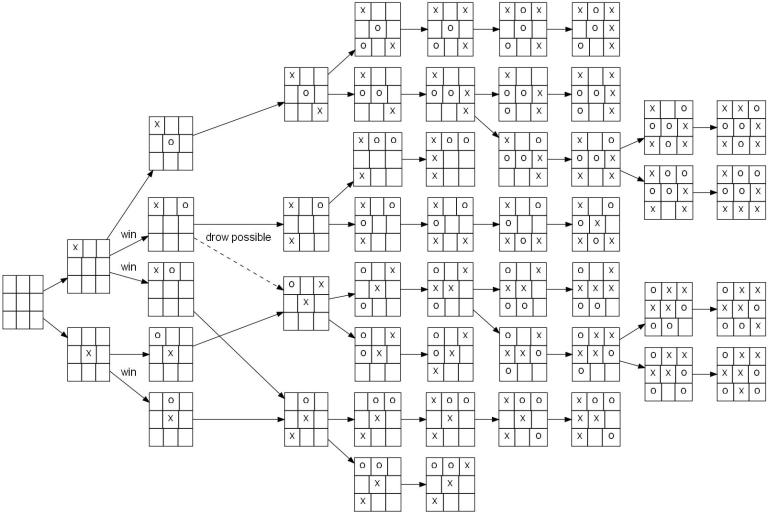
Tic-Tac-Toe的整個「遊戲樹」。圍棋的遊戲樹要比這個大上許多。(圖片來源:維基百科)
支持EJ Tech


如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
Related Posts








POPULAR POSTS
-
 Call的士APP|的士又傳加價?Call的士APP哪一款最熱門?電子支付回贈幾多?HK Taxi滿意度最高?
Call的士APP|的士又傳加價?Call的士APP哪一款最熱門?電子支付回贈幾多?HK Taxi滿意度最高?
-
 北上消費call車app|滴滴出行、高德打車超詳盡介紹!15公里40人仔有找!不下載都用得?
北上消費call車app|滴滴出行、高德打車超詳盡介紹!15公里40人仔有找!不下載都用得?
-
 生成式AI投資|生成式AI去年吸1968億 較前年飆8倍 美國佔61個模型佔主導 內地持專利最多
生成式AI投資|生成式AI去年吸1968億 較前年飆8倍 美國佔61個模型佔主導 內地持專利最多
-
 香港外賣App|Keeta 用無人機送外賣?Foodpanda 緊貼日常?Deliveroo 改策略吸客? 三大外賣平台、4月優惠一覽
香港外賣App|Keeta 用無人機送外賣?Foodpanda 緊貼日常?Deliveroo 改策略吸客? 三大外賣平台、4月優惠一覽
-
 個人電腦AI化|AMD今季推AI桌面CPU Ryzen PRO系列設16型號 第二季起支援惠普聯想等設備
個人電腦AI化|AMD今季推AI桌面CPU Ryzen PRO系列設16型號 第二季起支援惠普聯想等設備
-
 曇花一現?|iOS首款紅白機模擬器 作者出於恐懼主動下架
曇花一現?|iOS首款紅白機模擬器 作者出於恐懼主動下架
-
 Tesla 救人|美國男突發心臟病 靠Model Y保命
Tesla 救人|美國男突發心臟病 靠Model Y保命
-
 AI書寫偵測|Turnitin:全年600萬篇論文 八成內容為AI撰寫
AI書寫偵測|Turnitin:全年600萬篇論文 八成內容為AI撰寫
-
 foodpanda|賴偉昕:正面競爭推動行業進步 foodpanda數據分析回應市場變化 分析點餐喜好按區變陣
foodpanda|賴偉昕:正面競爭推動行業進步 foodpanda數據分析回應市場變化 分析點餐喜好按區變陣
-
 三星跑贏蘋果|本港5G網速測試 三星S24勝iPhone 15
三星跑贏蘋果|本港5G網速測試 三星S24勝iPhone 15

{kind=link}
{kind=link}